Using AWS Lambda Python functions and an API Gateway to deploy a URL Checker that looks for known malicious websites all while being serveless through Amazon Web Services.
Table of Contents
Overview
The goal here is to setup some AWS infrastructure so that we can send GET requests to an API and have it trigger our AWS Lambda function written in python to check against a database of URLs that give us response one whether or not the URL we provided is in fact a known malicious site. Additionally there will be a functionality to use the same API Gateway to POST new URLs to the database through a seperate Lambda function by using a seperate route. In the end we want to deploy this all automatically through just Terraform.
The flow will look like this: 
DynamoDB
I went with DynamoDB as it is a fully managed, serverless, NoSQL database. DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data export tools. Because the database backend wasn’t very complex and didn’t require multiple tables, but could grow to thousands of URLs, I wanted a non-relational database.
I started by building the DynamoDB using Terraform. I did this manually using the aws_dynamodb_table resource, but ran into a few issues. Eventually I switched to using the dynamodb-table AWS module from Anton Babenko for speed’s sake and a clean deploy.
I went with a Provisioned billing mode over On-Demand, as it was easy to limit the read/write capacity for this proof of concept, but it could easily be increased.
The database had a very simple attribute setup:
1
2
3
4
5
attributes = [
{
name = "BlacklistURL"
type = "S"
}
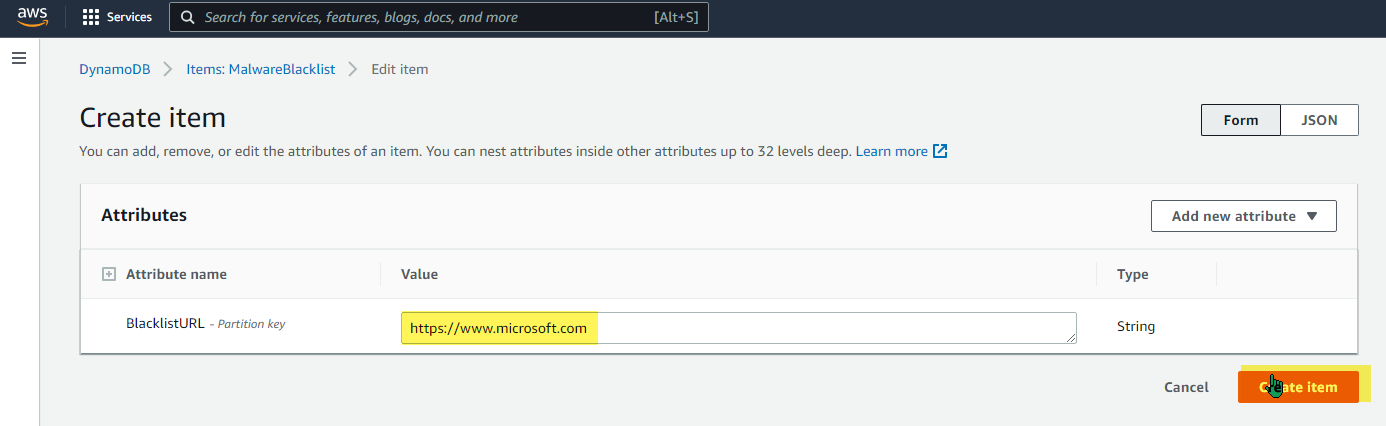
This sets up a way to store URLs as strings in “BlacklistURL”. Once I had the database built, I tested it by going to the AWS Console DynamoDB section, and manually adding a few items:
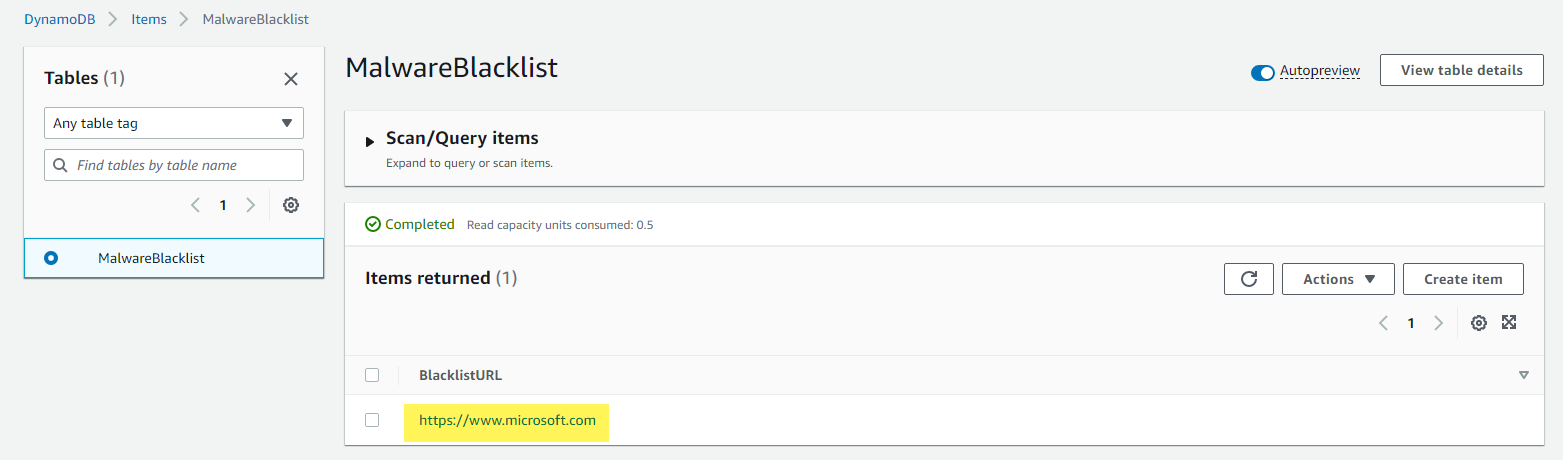
From the DynamoDB menus under Tables > Explore Items, I can see the items being successfully added:
dynamodb.tf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# --- dynamodb.tf ---
module "dynamodb_table" {
source = "terraform-aws-modules/dynamodb-table/aws"
name = "MalwareBlacklist"
hash_key = "BlacklistURL"
billing_mode = "PROVISIONED"
read_capacity = 10
write_capacity = 10
attributes = [
{
name = "BlacklistURL"
type = "S"
}
]
tags = {
Terraform = "true"
}
}
AWS Lambda Functions
Now that the database was set up and available in AWS, I had to start coding my Lambda functions. I decided to use Python, and I was aware of a few modules I could use to simplify my coding.
Boto3 is the AWS SDK for Python. It allows you to directly create, update, and delete AWS resources from your Python scripts. Now while I will be using Terraform for handling all of the infrastructure, this did give an easy way to interact with DynamoDB.
Although I could have used one Python script and had different behavior based on the event, I decided to have two separate Lambda functions to make the routing of the requests more logically separate. I started by building the getMalwareCheck.py function to read from the database and check for the URL, and then did the postMalwareCheck.py to add new values to the database.
I set up the client connection to the database, specified the table, and then set up a variable for the input to the function. I used the validators Python library to do a quick check on the input to make sure it was a proper URL.
Once the Python was ready, I was able to run it locally, providing hardcoded inputs, and verify if I was able to get results from the table properly, or add to the table; checking in the AWS Console.
Once everything checked out, I tested running the Lambda functions locally using the python-lambda-local project. I wrote some JSON files with the inputs that the functions would expect to get to test with as input.
Once that worked, I wrote the Terraform to build the Lambda functions. A very cool method I found is that you can specify a data object, that would auto-build the Python code as a zip file:
1
2
3
4
data "archive_file" "malware_post_zip" {
type = "zip"
source_file = "../python/postMalwareCheck.py"
output_path = "../python/postmalwarecheck.zip"
Note: that this only works in simple cases. If the deployment package is larger than 50MB, direct upload isn’t possible. Typically you would need to upload the zip file to an S3 bucket then call it to the Lambda function from there.
getMalwareCheck.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
#!/usr/bin/python3
import os
import boto3
import json
import validators
from boto3.dynamodb.conditions import Key
# Lambda Handler - cannot modify this method
def lambda_handler(event, context):
# Logging for CloudWatch
print(event)
dynamodb_client = boto3.client('dynamodb')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('MalwareBlacklist')
MalwareURL = event['queryStringParameters']['MalwareURL']
try:
# Validate that the input is a proper URL. Raise exception if it is not.
validurl=validators.url(MalwareURL)
if validurl==True:
# Query DynamoDB for the MalwareURL:
response = table.query(KeyConditionExpression=Key('BlacklistURL').eq(MalwareURL))
print(response)
# If the URL exists in the table, the ScannedCount will be > 0
if response['Count'] > 0:
return {
'statusCode': 200,
'body': json.dumps('URL is present in blacklist!')
}
elif response['Count'] == 0:
return {
'statusCode': 200,
'body': json.dumps('URL is not found in blacklist. Proceed.')
}
else:
return {
'statusCode': 400,
'body': json.dumps('We have problem with the count check')
}
raise Exception('We have a problem with the count check.')
else:
return {
'statusCode': 400,
'body': json.dumps('The URL is not valid.')
}
raise Exception('URL is not valid.')
except Exception:
return {
'statusCode': 400,
'body': json.dumps('There was a problem querying the blacklist.')
}
postMalwareCheck.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
postMalwareCheck.py
#!/usr/bin/python3
import os
import boto3
import json
import validators
from boto3.dynamodb.conditions import Key
# Lambda Handler - cannot modify this method
def lambda_handler(event, context):
# Logging for CloudWatch
print(event)
dynamodb = boto3.resource('dynamodb')
client = boto3.client('dynamodb')
table = dynamodb.Table('MalwareBlacklist')
MalwareURL = event['queryStringParameters']['MalwareURL']
# Putting a try/catch to log to the user when an error occurs posting the URL,
try:
# Validate if this is a valid URL. Raise exception if it is not,
valid=validators.url(MalwareURL)
if valid==True:
table.put_item(
Item={
'BlacklistURL': MalwareURL
}
)
return {
'statusCode': 200,
'body': json.dumps('New Malware URL Added to Blacklist Successfully!')
}
else:
raise
except:
return {
'statusCode': 400,
'body': json.dumps('Error adding new Malware URL to Blacklist.')
}
lambda.tf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# --- lambda.tf ---
data "aws_iam_policy_document" "lambda_assume_role_policy" {
statement {
effect = "Allow"
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
}
}
resource "aws_iam_role" "lambda_role" {
name = "lambda-lambdarole"
assume_role_policy = data.aws_iam_policy_document.lambda_assume_role_policy.json
inline_policy {
name = "allow_dynamodb"
policy = file("dynamodbpolicy.json")
}
}
resource "aws_lambda_layer_version" "lambda_layer" {
filename = "../lambdalayer/lambdalayer.zip"
layer_name = "lambdalayer"
compatible_runtimes = ["python3.9"]
}
data "archive_file" "malware_post_zip" {
type = "zip"
source_file = "../python/postMalwareCheck.py"
output_path = "../python/postmalwarecheck.zip"
}
resource "aws_lambda_function" "malware_post_function" {
function_name = "MalwarePostFunction"
filename = "../python/postmalwarecheck.zip"
source_code_hash = data.archive_file.malware_post_zip.output_base64sha256
role = aws_iam_role.lambda_role.arn
runtime = "python3.9"
handler = "postMalwareCheck.lambda_handler"
timeout = 10
layers = [aws_lambda_layer_version.lambda_layer.arn]
}
data "archive_file" "malware_get_zip" {
type = "zip"
source_file = "../python/getMalwareCheck.py"
output_path = "../python/getmalwarecheck.zip"
}
resource "aws_lambda_function" "malware_get_function" {
function_name = "MalwareGetFunction"
filename = "../python/getmalwarecheck.zip"
source_code_hash = data.archive_file.malware_get_zip.output_base64sha256
role = aws_iam_role.lambda_role.arn
runtime = "python3.9"
handler = "getMalwareCheck.lambda_handler"
timeout = 10
layers = [aws_lambda_layer_version.lambda_layer.arn]
}
dynamodbpolicy.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"dynamodb:BatchGetItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query",
"dynamodb:BatchWriteItem",
"dynamodb:PutItem",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem"
],
"Resource": "arn:aws:dynamodb:*"
}
]
}
Lambda Layer
Often times you see or hear of Python virtual environments that have all the dependencies for a particular Python program to run. In this case we are not on a local machine running our Python code, but we still need the proper environment for our dependencies to be available. We can accomplish this in AWS by using a Lambda Layer. With a Lambda Layer we are able to specify it easily in Terraform along with the Lambda functions, and could be reused for multiple functions. A Lambda layer is a .zip file archive that can contain additional code or other content. A layer can contain libraries, a custom runtime, data, or configuration files.
To Create a Lambda Layer
- Create a directory where we want to install our requests package:
mkdir -p layer/python/lib/python3.9/site-packages - Run
pip3 install <package> -t layer/python/lib/python3.9/site-packages/ - Access the layer folder:
cd layer - Zip the python folder containing all of the required files:
zip -r lambdalayer.zip * - Copy the zip file to a location where it can be referenced by Terraform.
Resulting Output for this Project: lambdalayer.zip
Once the Lambda Layer was added to the Terraform resources, I was able to test the Lambda functions successfully in the AWS console: 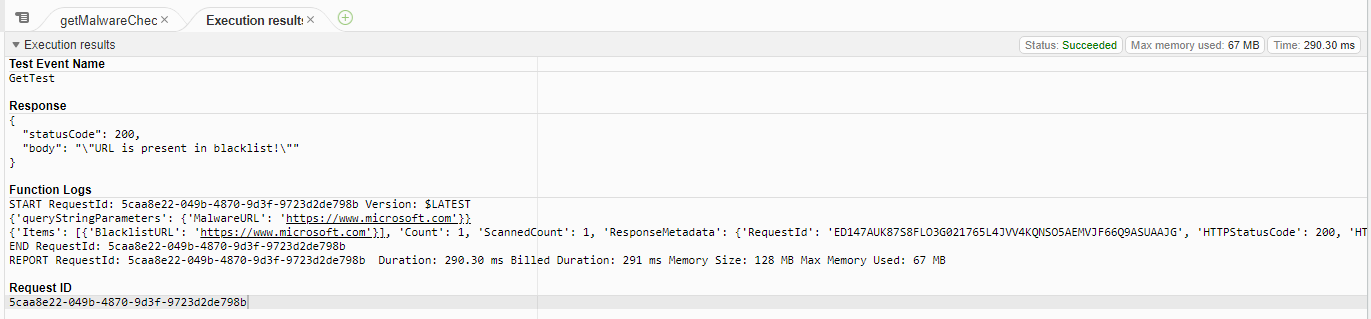
API Gateway
Using an HTTP API instead of a REST API made the most sense for this project as it is more of a proof of concept and learning experience rather than a full fledged deployed piece of infrastructure. It is also simple and straight forward while being cheaper.
Here is the main receipe for the API Gateway:
- Create the API Gateway itself.
- Create a Stage for deployment. In my case I used the $default stage, which was set to auto-deploy.
- Create two Routes for the HTTP GET or POST traffic to be picked up, and send to their respective integrations.
- Create two Integrations to pass the HTTP GET or POST traffic to be passed to the proper Lambda function.
- Add permissions so the API Gateway has permission to invoke the Lambda function.
apigateway.tf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# --- apigateway.tf ---
resource "aws_apigatewayv2_api" "lambdagateway" {
name = "malware_http_gateway"
description = "HTTP API Malware Check Gateway"
protocol_type = "HTTP"
}
resource "aws_apigatewayv2_stage" "lambdastage" {
api_id = aws_apigatewayv2_api.lambdagateway.id
name = "$default"
auto_deploy = true
access_log_settings {
destination_arn = aws_cloudwatch_log_group.api_gw.arn
format = jsonencode({
"requestId" : "$context.requestId",
"extendedRequestId" : "$context.extendedRequestId",
"ip" : "$context.identity.sourceIp",
"caller" : "$context.identity.caller",
"user" : "$context.identity.user",
"requestTime" : "$context.requestTime",
"httpMethod" : "$context.httpMethod",
"resourcePath" : "$context.resourcePath",
"status" : "$context.status",
"protocol" : "$context.protocol",
"responseLength" : "$context.responseLength",
"integrationErrorMessage" : "$context.integrationErrorMessage",
"errorMessage" : "$context.error.message",
"errorResponseType" : "$context.error.responseType"
})
}
}
resource "aws_apigatewayv2_route" "lambda_get_route" {
api_id = aws_apigatewayv2_api.lambdagateway.id
route_key = "GET /urlinfo/1"
target = "integrations/${aws_apigatewayv2_integration.lambda_get_integration.id}"
}
resource "aws_apigatewayv2_integration" "lambda_get_integration" {
description = "HTTP Integration HTTP GET to Lambda"
api_id = aws_apigatewayv2_api.lambdagateway.id
integration_type = "AWS_PROXY"
integration_method = "POST"
integration_uri = aws_lambda_function.malware_get_function.invoke_arn
passthrough_behavior = "WHEN_NO_MATCH"
}
resource "aws_apigatewayv2_route" "lambda_post_route" {
api_id = aws_apigatewayv2_api.lambdagateway.id
route_key = "POST /addurl"
target = "integrations/${aws_apigatewayv2_integration.lambda_post_integration.id}"
}
resource "aws_apigatewayv2_integration" "lambda_post_integration" {
description = "HTTP Integration HTTP POST to Lambda"
api_id = aws_apigatewayv2_api.lambdagateway.id
integration_type = "AWS_PROXY"
integration_method = "POST"
integration_uri = aws_lambda_function.malware_post_function.invoke_arn
passthrough_behavior = "WHEN_NO_MATCH"
}
resource "aws_lambda_permission" "api_gw_get" {
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.malware_get_function.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.lambdagateway.execution_arn}/*/*/*"
}
resource "aws_lambda_permission" "api_gw_post" {
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.malware_post_function.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.lambdagateway.execution_arn}/*/*/*"
}
CloudWatch
Although CloudWatch was not part of the original architecture, it was extremely valuable when troubleshooting and debugging. CloudWatch allows you to publish log groups from the various components to one place, making it easier to diagnose failures.
The first thing was to create the log groups for each component. I was mainly concerned with getting some data on what was coming in to the HTTP API Gateway, and what was coming in to the Lambda functions. I set up log groups for each of these, and a policy to allow give permissions for logging to CloudWatch.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# --- cloudwatch.tf ---
resource "aws_cloudwatch_log_group" "api_gw" {
name = "/aws/api_gw/${aws_apigatewayv2_api.lambdagateway.name}"
retention_in_days = 14
}
resource "aws_cloudwatch_log_group" "lambda_get" {
name = "/aws/lambda/${aws_lambda_function.malware_get_function.function_name}"
retention_in_days = 14
}
resource "aws_cloudwatch_log_group" "lambda_post" {
name = "/aws/lambda/${aws_lambda_function.malware_post_function.function_name}"
retention_in_days = 14
}
resource "aws_iam_policy" "lambda_logging" {
name = "lambda_logging"
path = "/"
description = "IAM policy for logging from a Lambda"
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*",
"Effect": "Allow"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "lambda_logs" {
role = aws_iam_role.lambda_role.name
policy_arn = aws_iam_policy.lambda_logging.arn
}
Test
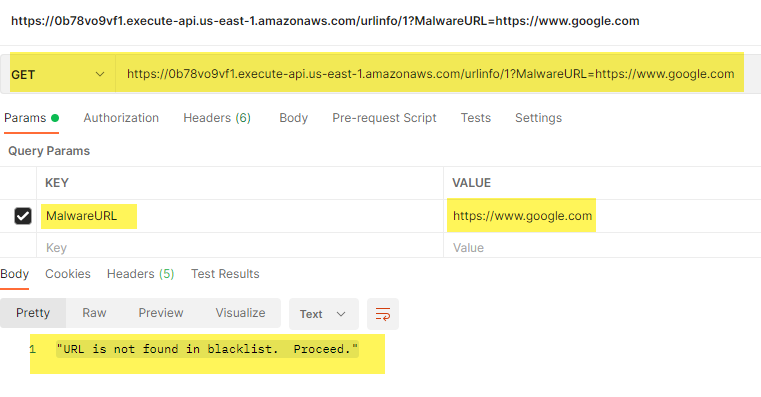
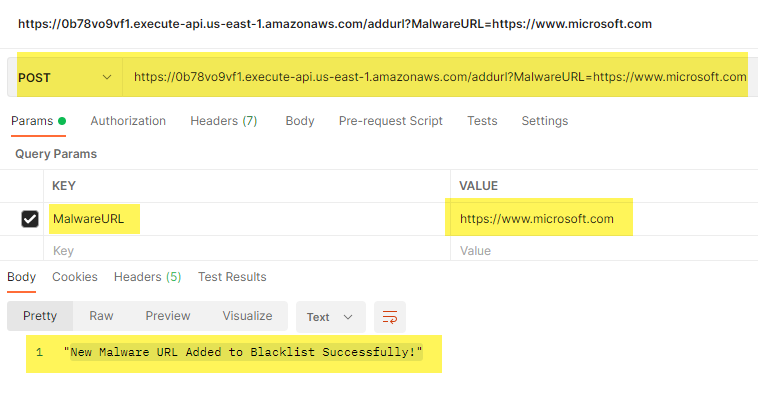
To test the entire setup, I mainly used Postman to craft HTTP GET and POST messages.
When testing with Postman, I could add the HTTP API Gateway Invoke URL, select the type of HTTP request, and add the MalwareURL as a parameter: